Abstract
Text-to-audio diffusion models produce high-quality and diverse music but many, if not most, of the SOTA models lack the fine-grained, time-varying controls essential for music production. ControlNet enables attaching external controls to a pre-trained generative model by cloning and fine-tuning its encoder on new conditionings. However, this approach incurs a large memory footprint and restricts users to a fixed set of controls. We propose a lightweight, modular architecture that considerably reduces parameter count while matching ControlNet in audio quality and condition adherence. Our method offers greater flexibility and significantly lower memory usage, enabling more efficient training and deployment of independent controls. We conduct extensive objective and subjective evaluations, see complete paper for more details.
*Research was completed while at an internship at Sony CSL - Paris
Architecture Overview
Our work, LiLAC, introduces a lightweight, parameter-efficient alternative to the commonly used ControlNet model for appending post-hoc controls to pre-trained models. Instead of cloning the backbone’s computationally expensive encoder blocks, we leverage the existing frozen blocks by performing a second pass through them, wrapped by small, trainable adaptor layers.
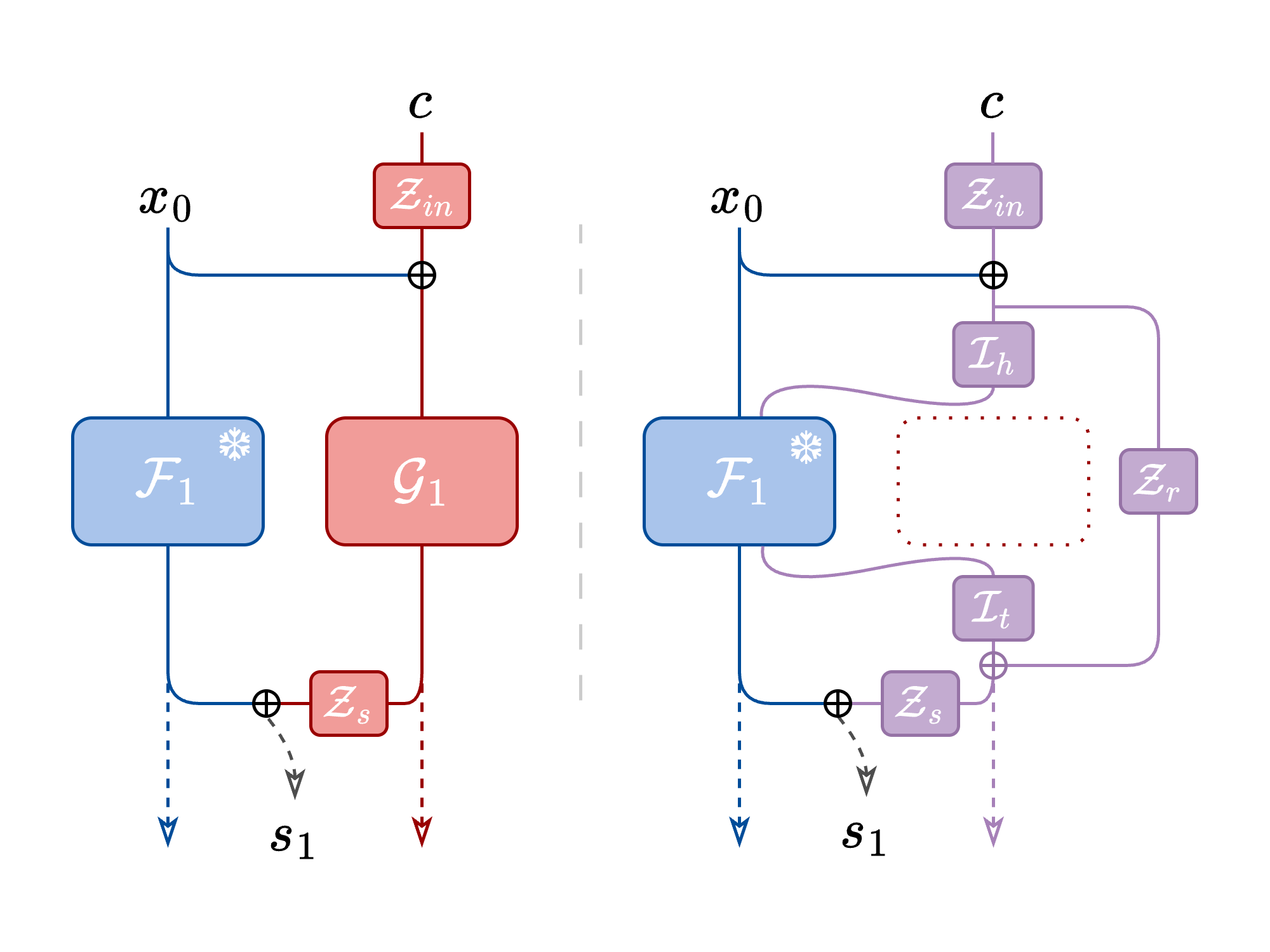
Specifically, we introduce three layers per encoder block as shown in the figure above:
- a Head layer before the frozen block
- a Tail layer after the frozen block
- a Residual connection to preserve condition information as it passes through the frozen block
To ensure training stability, we initialize the Head and Tail layers as Identity convolutions, which mirrors the backbone’s pathway from the start. The residual connection is initialized as a zero convolution, following the ControlNet methodology. This allows the conditional signal to be introduced gradually during training.
This design achieves a significant reduction in parameters while objective and subjective evaluations show it maintains comparable performance to the original ControlNet implementation. Using Diff-a-Riff as our backbone, our lightest configuration using only head layers (LiLACH) consists of only 32M parameters, a reduction of 81% compared to ControlNet’s 165M parameters. On heavier architectures such as Stable Audio Open this would provide a 90% reduction from 552M down to only 57M. This extra available parameter overhead allows for flexible and modular training of multiple independent controls without retraining the backbone model.
Audio Examples
This page presents a collection of randomly generated audio examples that demonstrate the capabilities of our proposed LiLAC architecture in comparison to traditional approaches. Each example consists of a 10-second audio segment generated using Diff-a-Riff as the backbone model, with a Classifier-Free Guidance (CFG) value of 0.25, 30 inference steps, and CLAP embedding for text conditioning.
For comprehensive comparison, we provide the following versions for each example:
- Original reference stem - The source audio
- LiLACH - Output from our lightweight head-only configuration
- LiLACHTR - Output from our optimal head-tail-residual configuration
- ControlNet - Output from the standard ControlNet architecture
- Unconditioned - Output generated without additional control conditioning
Below we showcase audio examples demonstrating both conditioning types explored in our paper - Chord and Chroma conditioning. Each example demonstrates how our model responds to different types of musical control signals. For detailed technical analysis of these conditions, please refer to the full paper linked above.
Chroma Conditioning
The chroma conditioning examples utilize chromagrams extracted directly from individual stems. Chromagrams represent the normalised intensity of different pitch classes (C, C#, D, etc.) over time, providing detailed harmonic data of the original audio. The models attempt to recreate audio with similar pitch content based on these chromagrams, while maintaining timbral characteristics specified by the CLAP embedding.
| Instrument | Original | LiLACH | LiLACHTR | ControlNet | Unconditioned | Chroma Condition |
|---|---|---|---|---|---|---|
| Woodwinds |  |
|||||
| Electric Guitar |  |
|||||
| Arpegiator |  |
|||||
| Guitar |  |
|||||
| Rhythm Electric Guitar |  |
|||||
| Electric Guitar |  |
|||||
| Piano |  |
|||||
| Electric Guitar |  |
|||||
| Electric Bass |  |
|||||
| Organ |  |
Chord Conditioning
For chord conditioning, we extracted chord progressions from full multitrack recordings. In the audio examples, these reference chords are panned right while the generated complementary stem is panned left. The chord conditions are represented similar to chromagrams: root notes have value 2, other chord notes value 1, and non-chord notes value 0. The generated audio’s instrumental characteristics are guided by CLAP embeddings.
| Instrument | Original | LiLACH | LiLACHTR | ControlNet | Unconditioned | Chord Condition |
|---|---|---|---|---|---|---|
| Woodwinds |  |
|||||
| Piano |  |
|||||
| Flute |  |
|||||
| Distorted Electric Guitar |  |
|||||
| String Section |  |
|||||
| Oboe |  |
|||||
| Hammond |  |
|||||
| Electric Guitar |  |
|||||
| Electric Piano |  |
|||||
| Acoustic Guitar |  |
|||||
| Acoustic Guitar |  |
|||||
| Synthesizer |  |
|||||
| Fiddle |  |
|||||
| Electric Bass |  |
|||||
| Upright Bass |  |